Project Cases Detail
MAGNA Steyr Fuel Systems compares elapsed time: Code-Aster versus Nastran
Comparisions of Code-Aster with NX.Nastran in terms of elapsed time have been done In a collaborative project between MAGNA Steyr Fuel Systems (Austria), Ingenieurbüro für Mechanik (Germany) and IMG Ingenieurbüro Michael Grabietz (Germany).
The codes employed are:
- NX.Nastran version 10.1 as included in the package "FEMAP with NX.Nastran" version 11.2. It runs on Windows 7
- Code-Aster version 12.3, compiled with MPI and PETSC for parallel computations, using gnu compilers. Running on OpenSuse 13.1
A part of the results is presented here.
Identic model and identic hardware for both codes
The FE-model investigated comprises 477859 TETRA10 elements and 746896 nodes, round about 2 Mio degrees of freedom. One linear static load case has been analysed.
All computations have been done on the same hardware: A workstation with a dual boot system with Windows 7 and openSUSE 13.1 installed.
- CPU: 6 x 3.4 GHz, Intel i7-4930
- RAM: 32 GB
The elapsed time comprises always a complete run, from reading the input file(s) to writing the output file containing the displacement field. The model size was choosen such that there should be always enough RAM to avoid memory swapping.
Comparision of direct solvers
The following 4 diagrams show the elapsed times for the direct solver(s) of Code-Aster (MULT_FRONT and MUMPS) and NX.Nastran. The MUMPS solver is employed with an "in-core" and with a "memory automatic" management. It was detected only afterwards that in case of "MUMPS in-core" and when running several MPI-processes (mpi_ncpu>1) the available RAM was too small, so that swapping of data occured which extended the elapsed time.
MULT_FRONT knows only the shared-memory parallelisation (OpenMP). The elapsed time is halfed when using about 3 or 4 processor cores.
MUMPS knows both, shared-memory (OpenMP) and distributed-memory (MPI) parallelisation. The results show that it is most effective to mix them: setting ncpu=2 and mpi_nbcpu=2 will always reduce the elapsed time compared to the same number of processors using only one of the both parallelisation methods (ncpu=4 and mpi_nbcpu=1 or ncpu=1 and mpi_nbcpu=4).
The direct solver of NX.Nastran uses shared memory.
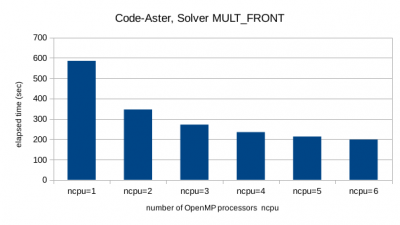

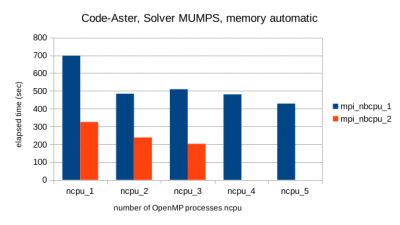

Conclusions
For the investigated model size the direct solver MUMPS (Code-Aster) has the best performance, in particular when used with both types of parallelism. This holds although MUMPS was the only solver which "lost" time due to swapping to the hard disk because 32 GB RAM did not suffice. NX.Nastran shows the longest elapsed times. MUMPS has the disadvantage of the largest need of RAM.
When doing the same kind of comparision for extremly large models MUMPS (Code-Aster) is even more advantageous in terms of elapsed time due to it's scalability with MPI. The problem of the increasing demand of RAM can be attenuated by distributing the calculation over different computing nodes of a cluster.